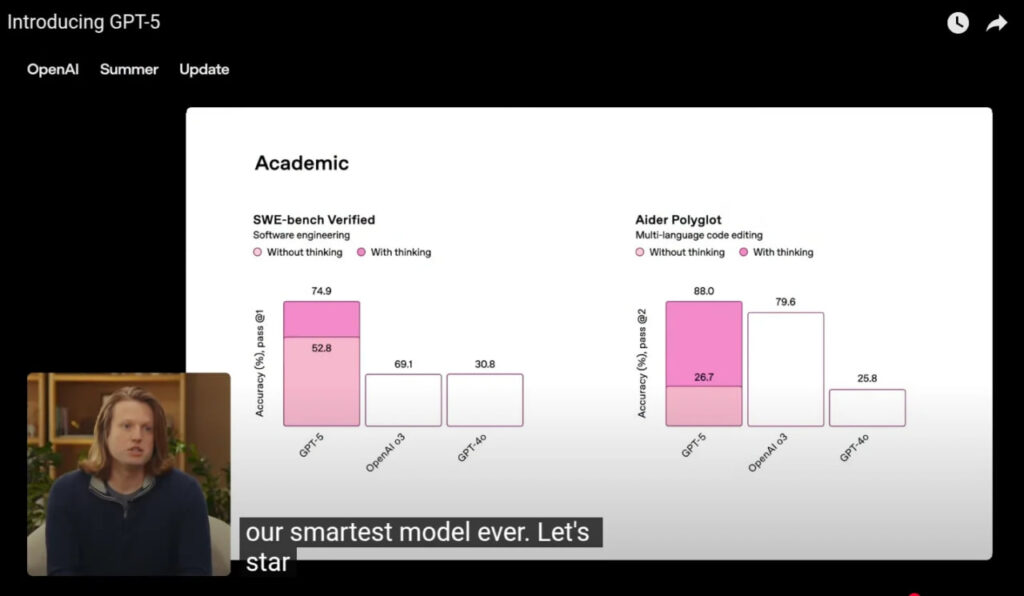
در جریان رویداد معرفی GPT-5 که شب گذشته برگزار شد، OpenAI چند نمودار را نمایش داد که عملکرد مدل جدید را بسیار چشمگیر نشان میدادند. اما با کمی دقت، مشخص شد برخی از این نمودارها مشکل بزرگی دارند که باعث میشود مصرفکنندگان درک درستی از پیشرفت GPT-5 نداشته باشند.
براساس گزارش ورج، یکی از نمودارهای نمایش داده شده مربوط به ارزیابی «فریب» مدلها بوده که مقیاس آن بهطور عجیبوغریبی نامرتب بوده است. برای مثال، در بخش «فریب در کدنویسی»، نمودار روی صحنه نشان میداد که GPT-5 در حالت «با تفکر» نرخ فریب ۵۰ درصدی دارد. این عدد با نرخ ۴۷.۴ درصدی مدل کوچکتر o3 مقایسه شده بود، اما ستون مربوط به o3 به شکل غیرمنطقی بلندتر ترسیم شده است.
نکته جالب دیگر اینکه در وبلاگ رسمی OpenAI ارقام متفاوت و درستتری وجود دارد و در آن نرخ فریب GPT-5 برابر با ۱۶.۵ درصد ذکر شده است.
مشکل بزرگ نمودارهای مربوط به GPT-5
همانطور که در تصویر زیر قابل مشاهده است، امتیازات o3 و GPT-4o در بنچمارک SWE-bench Verified اعداد متفاوتی را نشان میدهد اما اندازه ستون آنها یکسان ترسیم شده است. همچنین GPT-۵ با وجود اختلاف ۵ امتیازی نسبت به o3 ستون بسیار بلندتری دارد.
این اشتباهات بهقدری واضح بوده و با انتقاد کاربران در شبکههای اجتماعی همراه بود که «سم آلتمن، مدیرعامل OpenAI، آن را «اشتباه بزرگ نموداری» نامید و گفت نسخه صحیح در وبسایت شرکت منتشر شده است.
یکی از اعضای تیم بازاریابی OpenAI هم عذرخواهی کرده و در پست خود نوشت:
«نمودار را در وبلاگ اصلاح کردیم، دوستان. بابت این خطای ناخواسته عذرخواهی میکنیم.»
OpenAI تاکنون به درخواست رسانهها برای اظهار نظر بیشتر پاسخ نداده است. مشخص نیست این نمودارها با کمک GPT-5 تهیه شدهاند یا خیر، اما چنین خطایی در روز رونمایی بزرگ، آن هم زمانی که شرکت روی «پیشرفت چشمگیر در کاهش خطاها و توهمات» مدل جدید تاکید داشت، چندان خوشایند به نظر نمیرسد.